基于Python去水印
一、整体流程概览
用YOLOv8自动检测图片里的水印区域,得到水印的“掩码图”mask(即黑白图,白色是水印)
用 lama-cleaner 命令行(支持自定义mask)对原图+掩码批量自动修复,得到无水印图
全程批量自动,不用人工一张张画框
路径是:/src/weibo/rmwatermarks:
mask.py、lama-cleaner.py、venv、models
二、详细分步教程
Step 1. 环境准备
使用Python 3.10创建一个venv环境(推荐,避免torch等AI包兼容性问题)
1 | |
1 | |
Step 2. 安装去水印工具以及依赖
[!IMPORTANT]
安装ultralytics, 是一个专注于人工智能视觉检测,尤其是目标检测(Object Detection)领域的开源项目和公司。它最著名的产品是 YOLO(You Only Look Once)系列模型的官方实现
huggingface_hub,是huggingface/diffusers/transformers 系列模型托管和下载的基础包,很多 AI 项目都会自动带上
lama-cleaner,由 SOTA AI 模型提供支持的免费开源修复工具
编辑requirements.txt文件
1 | |
1 | |
Step 3. 下载/准备YOLOv8水印检测模型
[!IMPORTANT]
可以直接用开源训练好的通用水印检测模型,比如这个yolov5-watermark(适配微博/公众号/小红书等)
将后缀为pt的模型放在以下文件夹中,这是我的模型:best.pt
下载地址:https://pan.baidu.com/s/1xRzBTlBlDk0vM980rgB79g 提取码: hui9
放在:src/weibo/rmwatermarks/models/
lama-cleaner 是基于“大LAMA模型(big-lama)”的 inpainting 修复工具,这个也是必须,省的lama-cleaner报错
下载地址:https://pan.baidu.com/s/10Q6cls-XbgH-ggF9LCetWQ 提取码: hui9
放在:~/.cache/torch/hub/checkpoints/big-lama.pt
big-lama.pt 就是 Lama 模型的核心“权重文件”(model checkpoint),是神经网络的所有参数,本地没这个文件,模型根本没法运行
工作流程:
首次启动 lama-cleaner(无 big-lama.pt),程序会自动联网下载官方权重包到你的缓存目录(默认 PyTorch 习惯是 ~/.cache/torch/hub/checkpoints/)。
下好后永久复用。你之后每次启动 lama-cleaner、调用 inpaint,都会直接加载这个 big-lama.pt
如果你删除 big-lama.pt,lama-cleaner 会再次自动下载(只要本地没找到权重文件)
Step 4. 批量检测所有图片,导出mask
新建检测脚本(这是我的路径你们可以选择自己的)
1 | |
1 | |
运行:python3.10 mask.py
验证mask图和去水印图片是否一致(可跳过)
1 | |
1 | |
Step 5. 用 lama-cleaner 批量修复去水印(自动读取mask)
编写批处理脚本
1 | |
[!IMPORTANT]
每张图片都会用同名mask修复水印区域,输出到 image_nowm/
1 | |
[!IMPORTANT]
首先运行
lama-cleaner --model lama --host 127.0.0.1 --port 8188 --debug提示如下信息就代表成功
1 | |
然后运行:python3.10 lama-cleaner.py
所有去掉水印的图片都保存在:/src/weibo/rmwatermarks/image_nowm/
以上是已有模型进行的去水印,下面是训练自己的去水印模型⬇️
请注意自己的路径,以下是全新的路径,唯独共用一个venv
三、训练去水印模型
Step 1.前提训练模型前,需要大量手动给有水印的图片加矩形选区,这里我推荐以下两款工具
[!IMPORTANT]
labelImg本地
这里我选择labelImg本地进行绘制,目前文件路径为:
src/weibo/rmwatermarks:
- labelImg 下载地址: https://pan.baidu.com/s/19WwEaa2PM_M_GTnMUsSZSA 提取码: hui9
- trainingmodel 自行创建,我这里觉得分类好方便
src/weibo/rmwatermarks/trainingmodel:
dataset 自行创建(必须)
train_val.py 自行创建(代码如下)这是为了划分train和val图片,先不要运行!!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import os
import random
import shutil
# 1. 原始数据目录,图片和txt一一对应、都在里面
src_dir = '/home/zjh/src/weibo/rmwatermarks/trainingmodel/dataset/datasource' # 修改为你的原始数据目录
dst_dir = '/home/zjh/src/weibo/rmwatermarks/trainingmodel/dataset'
# 2. 输出目录结构
images_train = os.path.join(dst_dir, 'images', 'train')
images_val = os.path.join(dst_dir, 'images', 'val')
labels_train = os.path.join(dst_dir, 'labels', 'train')
labels_val = os.path.join(dst_dir, 'labels', 'val')
for d in [images_train, images_val, labels_train, labels_val]:
os.makedirs(d, exist_ok=True)
# 3. 获取所有图片(支持jpg、jpeg、png)
img_exts = ('.jpg', '.jpeg', '.png')
imgs = [f for f in os.listdir(src_dir) if f.lower().endswith(img_exts)]
random.shuffle(imgs) # 打乱顺序
val_ratio = 0.2 # 验证集比例
num_val = int(len(imgs) * val_ratio)
val_imgs = imgs[:num_val]
train_imgs = imgs[num_val:]
def copy_pair(imgs, img_dst, label_dst):
for img in imgs:
base = os.path.splitext(img)[0]
img_path = os.path.join(src_dir, img)
label_path = os.path.join(src_dir, base + '.txt')
if not os.path.exists(label_path):
print(f'标签文件缺失: {label_path},跳过。')
continue
shutil.copy(img_path, os.path.join(img_dst, img))
shutil.copy(label_path, os.path.join(label_dst, base + '.txt'))
copy_pair(train_imgs, images_train, labels_train)
copy_pair(val_imgs, images_val, labels_val)
print(f"划分完成,train: {len(train_imgs)},val: {len(val_imgs)}")watermark.yaml 自行创建(代码如下)
1
2
3
4
5
6path: src/weibo/rmwatermarks/trainingmodel/dataset/
train: images/train
val: images/val
names:
0: watermark
src/weibo/rmwatermarks/trainingmodel/dataset:
- datasource 自行创建(必须)在这里面放入要画矩形的水印图片
- images 自动生成
- labels 自动生成
- classes.txt 自动生成
Step 2.运行labelImg工具(可选venv环境)
安装所需依赖
[!TIP]
根据自己的系统来安装(如果不用venv环境,就在系统中安装以下命令)(venv默认已经安装PyQt5的)
1 | |
[!IMPORTANT]
上面我已经放了labelImg的下载地址,解压出来cd labelImg,运行以下命令
1 | |
打开目录:src/weibo/rmwatermarks/trainingmodel/dataset/images/这里我们前面已经交代了,通过如下图片进行选区保存等
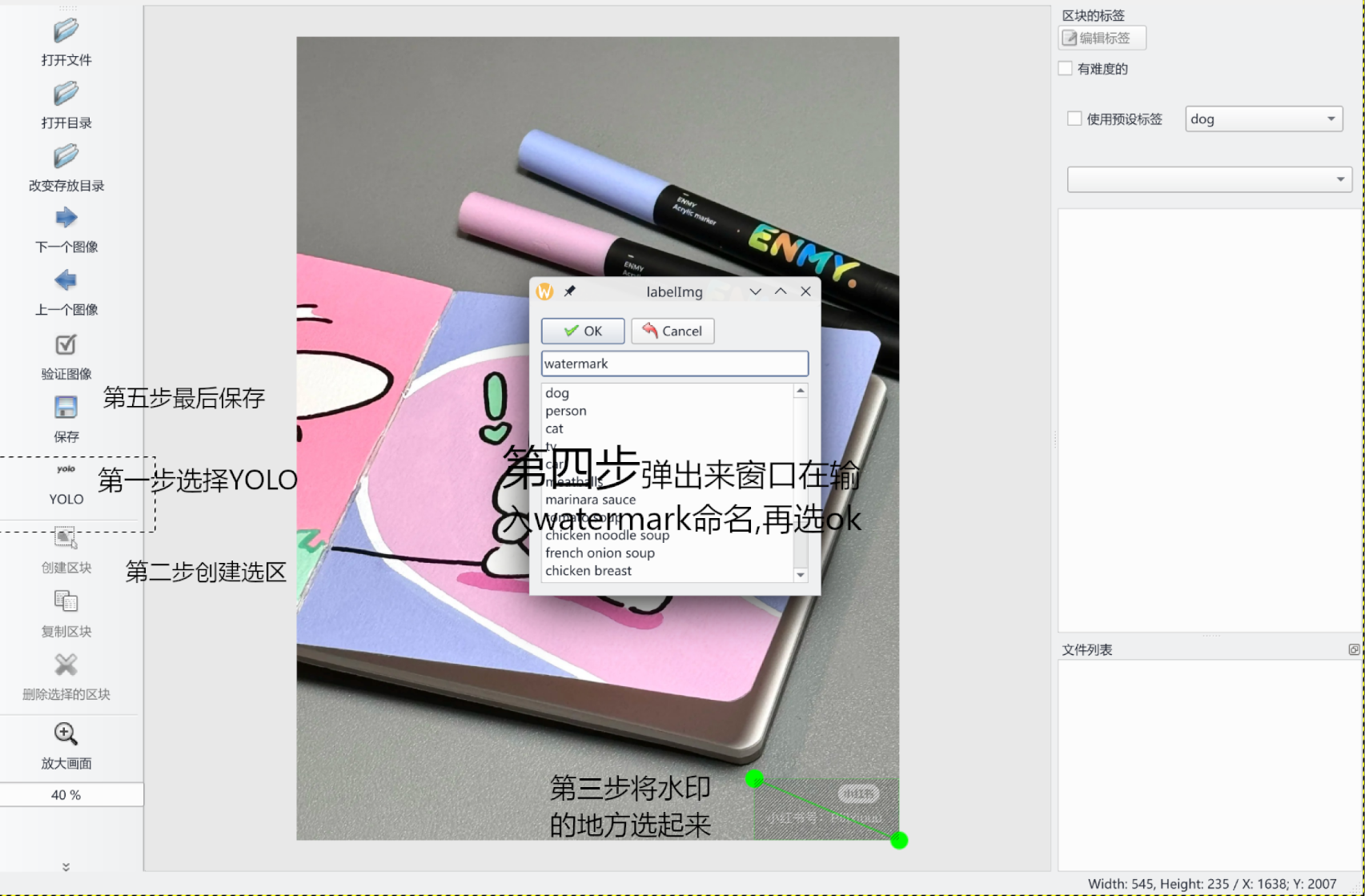
[!IMPORTANT]
选区完成之后可以看到我们datasource下有很多图片以及txt文件
运行train_val.py将txt和图片分类开
python3.10 train_val.py以下两种文件就生成了
- labels 里面装着txt文件
- images 里面就是画好选区的图片
- datasource 这个数据源就可以删除了,也可以不删除
Step 3.正式编写模型(需要venv环境)
1 | |
[!IMPORTANT]
data=trainingmodel/watermark.yaml根据自己的路径改
**这里需要一个yolov8n.pt官方的模型,下载链接:https://pan.baidu.com/s/1fyq6qhjnkglEj4cflSDvjg 提取码: hui9 **
把他放在和venv同目录下,也就是我们目前的src/weibo/rmwatermarks/目录下
运行以下命令:
1 | |
出现以下等等信息代表成功,模型放在src/weibo/rmwatermarks/runs/detect/train/weights/best.pt
1 | |